PostgreSQLのインデックスによる実行時間の短縮効果
PostgreSQLのテーブルを作成してインデックスの設定を当たり前のようにしているが、インデックスを設定する/しないでどのぐらいの差が出るのかをあまり試したことがなかった。
今回は、簡単なテーブルでインデックスの効果を試してみることにする。
環境
インデックスの効果を試す環境は次の通り。
VM環境で実施。
| OS /MW | Version |
|---|---|
| CentOS | 8 |
| PostgreSQL | 13 |
テーブル情報
| カラム | 型 |
|---|---|
| id | シーケンス |
| name | varchar(30) |
| memo | text |
| regist_time | timestamp |
実施したこと
11万件、100万件、500万件、1000万件で各件数の際にインデックスを作成し実行時間を測定。
実行時間は、EXPLAIN ANALYZEで測定しました。
regist_timeカラムでインデックスを作成し、SELECT文でregist_timeカラムをWHERE句に指定するようにしています。
測定に指定するregist_timeの値は各件数のときは同じものを指定していますが、別々の件数では同じものを指定していないのは失敗でした。
測定結果
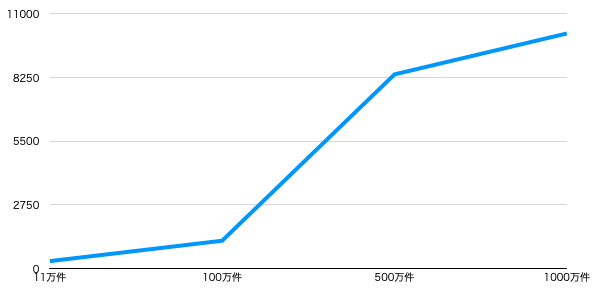
インデックスの効果がかなり現れる結果になった。
11万件の時点で、すでに300倍検索スピードが上がっている。
1000万件となると1万倍も検索性能に違いが現れている。

グラフにしてみると性能差がよくわかる。
特に100万件と500万件の間で大きく検索性能が向上している。
測定結果から見えたこと
測定してみたことで見えたこととしては、11万件ではシーケンシャルスキャンを実施していたが、100万件ではパラレルシーケンシャルスキャンで動作していることが分かった。
PostgreSQLの9.6から導入されているようで、シーケンシャルスキャンもパラレルで動くようになっているとは知らなかった。
今回は、Core数も3だったこともあり、並列度は2で動作していた。
Core数がもう少し多いと並列度が増えてインデックスなしでももう少し検索スピードは向上するかもしれない。
まとめ
インデックスあり/なしでの実行時間の短縮効果を調べていることで、知らなかったパラレルシーケンススキャンを知ることができた。複数インデックスでの検索性能の向上についても引き続き調べてみようと思う。
測定で使用したコマンドなど
テーブル
CREATE SEQUENCE seq_id; CREATE TABLE test1 ( id int PRIMARY KEY DEFAULT nextval('seq_id'), name varchar(30), memo text, regist_time timestamp );
データ蓄積のためスクリプト
#!/bin/bash max=100000 echo "Start!!" filename=sample.sql count=0 while true do if [[ ${count} -eq ${max} ]] ; then break fi if [[ $((count % 2)) = 0 ]] ; then name1="Tanaka" memo1="Insert Data. Chikuseki data$(date)" else name1="Sato" memo1="Search Data. CHikuseki data$(date). iiiaaiiiiiaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa" fi sql="INSERT INTO test1 (name, memo, regist_time) VALUES ('"${name1}"', '"${memo1}"', now());" echo "${sql}" >> ${filename} count=$((count + 1)) done echo "Insert Table!!" psql -d testdb -f ${filename} rm ${filename} echo "End!!"
参考
パラレスシーケンススキャンについて
PostgreSQL 9.6のパラレルシーケンシャルスキャンを検証する